
Diafiltration Cost Uncertainty Quantification and Propagation#
Uncertainties in market conditions—such as lithium price fluctuations over the past decade (illustrated below)—can significantly influence technology selection and investment decisions. In critical mineral recovery plant, stakeholders and investors are often interested in understanding:
Which technical or economic parameters most strongly affect the cost of recovery?
How sensitive is system performance to market volatility?
How do uncertain inputs propagate through the process model and impact key decision indicators?
These questions are particularly important for emerging technologies where both market and process uncertainties remain substantial.
In this tutorial, we study a diafiltration process for lithium and cobal recovery under costing and unit model parameter uncertainty. We explore how uncertainty in key parameters propagates to a key performance indicator: cost of recovery.
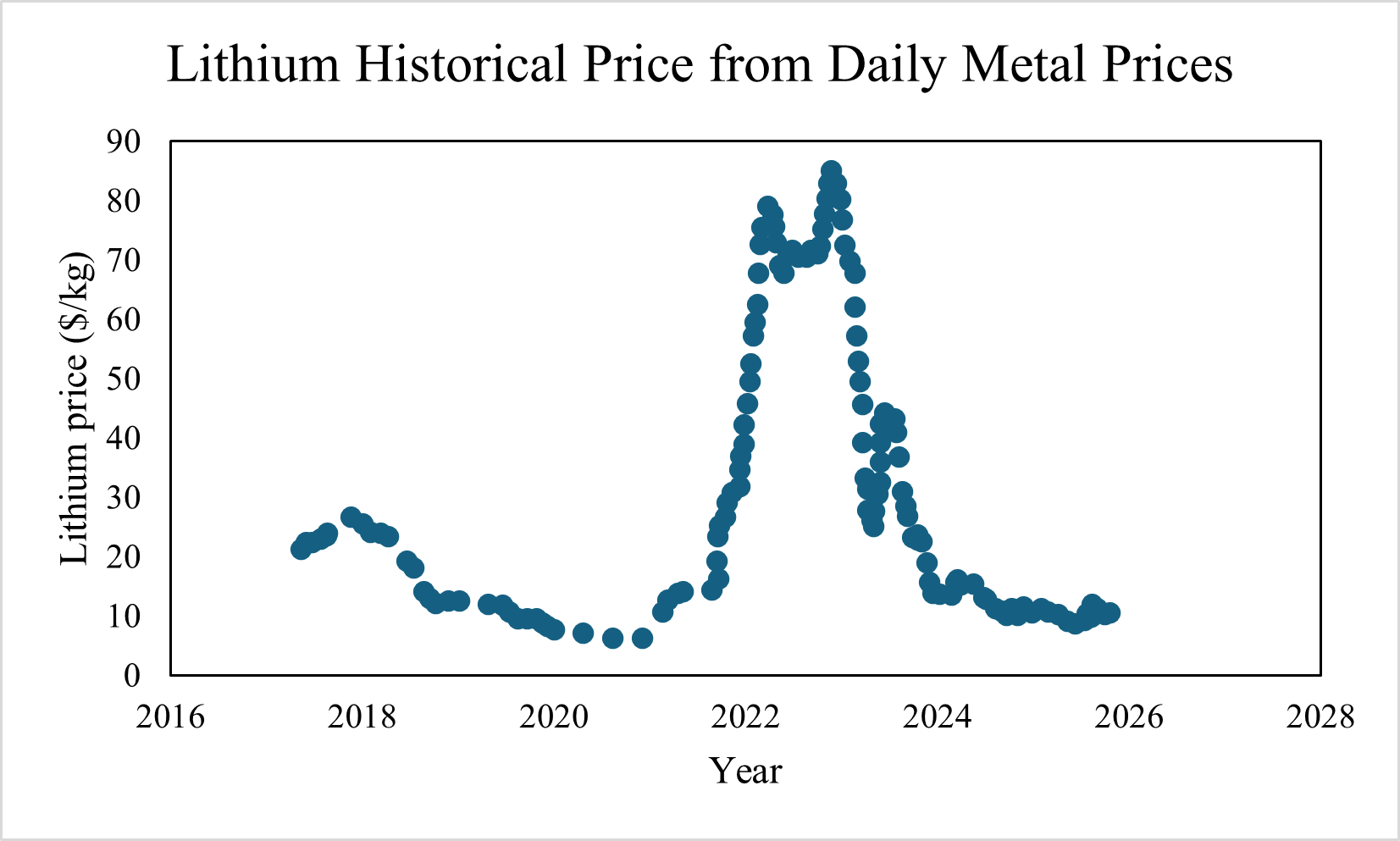
A range of uncertainty modeling approaches and sampling strategies are demonstrated, including the development of probability distributions from historical data.
In this tutorial, you will learn how to:
Define alternative technology scenarios (e.g., different membrane sieving coefficients)
Identify and specify uncertain model parameters
Construct probability distributions
Select appropriate sampling strategies
Run optimization for selected samples
Analyze and visualize results to support decision making
By the end of this tutorial, you will have a structured workflow for performing uncertainty quantification in a process modeling and costing framework.
Step 1: Imports and Setup#
Import necessary packages.
import os
import pyomo.environ as pyo
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import prommis.costing.uq.diafiltration_cost_uq as uq
import logging
Step 2: UQ Model Specification#
Step 2.1: Build model and specify variables and bounds#
After importing the required packages, the next step is to construct the diafiltration model and define the decision variables along with their bounds. Use build_diafiltration_model function to build the model. Within the build_diafiltration_model function, the diafiltration model is built, initialized, has costing applied to it, and is solved for the deterministic minimum cost of recovery. For details, please see here.
Later, call the decision_variables_bounds function to activate the decision variables and their bounds.
In this case study, the membrane stage lengths are identified as decision variables. Their bounds are specified based on literature values reported in: Wamble, N.P., Eugene, E.A., Phillip, W.A., Dowling, A.W., ‘Optimal Diafiltration Membrane Cascades Enable Green Recycling of Spent Lithium-Ion Batteries’, ACS Sustainable Chem. Eng. 2022, 10, 12207−12225.
Variables |
lower bound |
upper bound |
units |
|---|---|---|---|
stage1 length |
0.1 |
10000 |
m |
stage2 length |
0.1 |
10000 |
m |
stage3 length |
0.1 |
10000 |
m |
# Silence warnings for better results view
logging.getLogger("pyomo").setLevel(logging.ERROR)
# Build the model with default contributes
build_diafiltration_model = uq.build_diafiltration_model(
sieving_coeffs=(1.3, 0.5), technology_name=None
)
# Now the variables of the diafiltraiton process related variables is available,
# and can be accessed to set boundaries
decision_variables_bounds = uq.decision_variables_bounds(build_diafiltration_model)
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage1: Stream Initialization Completed.
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage1: Initialization Completed, optimal - <undefined>
2026-04-23 15:27:17 [INFO] idaes.init.fs.mix1: Initialization Complete: optimal - <undefined>
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage2: Stream Initialization Completed.
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage2: Initialization Completed, optimal - <undefined>
2026-04-23 15:27:17 [INFO] idaes.init.fs.mix2: Initialization Complete: optimal - <undefined>
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage3: Stream Initialization Completed.
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage3: Initialization Completed, optimal - <undefined>
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage3: Stream Initialization Completed.
2026-04-23 15:27:17 [INFO] idaes.init.fs.stage3: Initialization Completed, optimal - <undefined>
Step 2.2: Identify uncertain parameters#
There are uncertainties associated with both market prices and process-related parameters. For the purpose of demonstration, the uncertainties ideantified here are not exhaustive; rather, we focus on the most influential parameters.
All cost used in this study are converted to 2021 dollars.
Market-Related Uncertainties
Membrane cost (\(\$/\text{m}^2\)). Membrane unit price changes as technology advances and manufacturing scales evolve. A cost range of [36, 450] (\(\$/\text{m}^2\)) is referenced from the literature.
Electricity cost (\(\$/\text{kWh}\)). Electricity prices fluctuate daily, seasonally, and by location. In this case study, daily electricity prices from Pennsylvania (PA) over the past ten years are used. Data are obtained from U.S. Energy Information Administration.
Lithium price (\(\$/\text{kg}\)). Lithium prices vary significantly due to global supply-demand dynamics. Historical data from the past eight years are used in this study, referenced from Daily Metal Prices.
Cobalt price (\(\$/\text{kg}\)). Similar to lithium, cobalt prices fluctuate frequently. Historical data from the past ten years are used, sourced from trading economics.
Corporate Income tax rate (%). Income tax rate affects operating costs and includes both federal and state components. Tax rates do not change frequently, although state-level adjustments may occur periodically (typically annually at most). To maintain consistency, the PA state income tax rate is used in this study. Reference: Tax Foundation.
Royalty charge percentage of revenue (%). Royalty rates vary across plants and technologies. Literature reports typical ranges between 1% to 7%. References include: 1, 2, 3, 4
Process and Operational Uncertianties:
Membrane replacement factor (\(\#/\text{year}\)). Due to fouling, membranes typically require replacement every 5-10 years.
Pump efficiency (dimensionless). Pumps are major pieces of equipment in the diafiltration process. Their efficiency directly impacts energy consumption and operating cost. Literature reports that pump efficiency can range from 0.1 to 1.
Operating days per year (days/year). Process plants may shut down periodically for maintenance or operational adjustments, resulting in fewer than 365 operating days annually. In this study, the operating days are assumed to range from 300 to 365 days per year.
Lang factor (dimensionless). The Lang factor accounts for indirect capital costs such as installation, piping, construction labor, plant services, and site improvements, etc. Details are provided in the PrOMMiS costing. Depending on process specifications, the Lang factor typically ranges from 2 to 5.93. Reference: Seider, W. D., Lewin, D. R., Seader, J. D., Widagdo, S., Gani, R., Ng, K. M. (2017). Product and Process Design Principles: Synthesis, Analysis and Evaluation. United Kingdom: Wiley.
# Identify uncertain parameters
uncertain_parameters = uq.identify_uncertain_params(build_diafiltration_model)
Step 2.3: Assign uncertainty distribtutions#
After identifying and defining the uncertain parameters, the next step is to assign appropriate probability distributions to represent their uncertainty.
According to the NASA cost estimating handbook, triangular distributions are commonly applied to work breakdown structure element when limited data are available but reasonable estimates of minimum, most likely, and maximum values exist. In this study, pump efficiency, membrane cost, and operating days per year are modeled using triangular distributions. These parameters typically have a preferred (mode) value, along with referenced or assumed lower and upper bounds.
Lognormal distributions are widely used in cost and price analysis. Compared to the normal distribution, the lognormal distribution is strictly nonnegative and right-skewed. Commodity prices such as electricity, lithium, and cobalt are unlikely to take negative values and often exhibit upward skewness due to supply constraints and market volatility. In contrast, the normal distribution is symmetric and allows negative values, which are not appropriate for modeling prices. Therefore, the lognormal distribution is preferred for representing resource and material price uncertainty.
A helper function is provided to construct lognormal distributions directly from historical data. Users may replace the provided .csv files with their own datasets. When doing so, ensure that the file path correctly points to the stored data location.
For parameters with limited references but known lower and upper bounds, a uniform distribution is applied. This approach is used for the membrane replacement factor, Lang factor, royalty charge percentage of revenue, and income tax rate when sufficient historical data are not available.
Users may also define and use alternative uncertainty distribution methods if more appropriate for their specific application.
# Directory for historical data
script_dir = uq.get_script_dir()
# Lognormal params from historical data
# Lithium price USD/kg
li_file = os.path.join(script_dir, "lithium_price_USA_dailymetalprice_yr2021.csv")
li_df = pd.read_csv(li_file)
li_data = li_df["2021_$/kg"].values
mu_li, sigma_li = uq.estimate_lognormal_params_from_data(li_data)
# Cobalt price USD/kg
co_file = os.path.join(script_dir, "cobalt_price_USA_tradingeconomics_yr2021.csv")
co_df = pd.read_csv(co_file)
co_data = co_df["2021_$/kg"].values
mu_co, sigma_co = uq.estimate_lognormal_params_from_data(co_data)
# Electricity price of Pennsylvania
elec_file = os.path.join(script_dir, "iea_1990_2025_industry_elec_monthly_price_PA.csv")
elec_df = pd.read_csv(elec_file)
elec_data = elec_df["PA_2021_$/kWh"].values
mu_elec, sigma_elec = uq.estimate_lognormal_params_from_data(elec_data)
# Determine what distribution is in lognormal distribution
cp = build_diafiltration_model.fs.costing
lognormal_params = {
cp.electricity_cost.getname(): {"mu": mu_elec, "sigma": sigma_elec},
cp.Li_price.getname(): {"mu": mu_li, "sigma": sigma_li},
cp.Co_price.getname(): {"mu": mu_co, "sigma": sigma_co},
}
# Income tax empirical samples
income_tax_file = os.path.join(script_dir, "PA_income_tax.csv")
income_tax_samples = uq.load_income_tax_samples_from_csv(
income_tax_file, column_name="2021_tax"
)
# Assign uncertainty specs for uncertain parameters
uncertainty_specs = uq.build_uncertainty_specs(
build_diafiltration_model,
lognormal_params=lognormal_params,
income_tax_samples=income_tax_samples,
)
Step 3: Sampling methods#
Once the uncertain parameters have been defined and their probability distributions assigned, the next step is to generate samples that represent these distributions.
In general, a larger sample size provides a better representation of the underlying distributions. However, increasing the sample size also increases computational cost. To balance statistical reliability and computational efficiency, a sample size of 200 is used in this case study. On a typical workstation, this requires approximately two minutes to complete. Users who wish to explore larger sample sizes are encouraged to run the analysis locally, where longer computational times can be accommodated.
Two sampling methods are available in this model, and all uncertain parameters are sampled independently:
Latin Hypercube Sampling (LHS)
Monte Carlo sampling
Both methods independently sample the 10 uncertain parameters, meaning that no correlations are assumed among them. If correlations between parameters are relevant for a specific study, additional modeling considerations would be required.
# Set sample size
n_samples = 200
# Choose between LHS and Monte Carlo sampling method.
# Change use_lhs=False to activate Monte Carlo sampling method.
use_lhs = False
# Set up solver
max_iter = 5000
tol = 1e-6
acceptable_tol = 1e-5
local_solver = pyo.SolverFactory("ipopt")
local_solver.options["max_iter"] = max_iter
local_solver.options["tol"] = tol
local_solver.options["acceptable_tol"] = acceptable_tol
random_seed = 1
def choose_sampling(
m,
uncertain_params,
uncertainty_specs,
n_samples,
solver=local_solver,
random_seed=1,
):
if use_lhs:
# LHS sampling and solve the model.
samples = uq.run_LHS(
m,
uncertain_params,
uncertainty_specs,
n_samples=n_samples,
solver=local_solver, # Default IPOPT
random_seed=random_seed,
)
else:
# Monte carlo sampling and solve the model
samples = uq.run_monte_carlo(
m,
uncertain_params,
uncertainty_specs,
n_samples=n_samples,
solver=local_solver, # Default IPOPT
random_seed=random_seed,
)
return samples
After executing the previous cell, the uncertainty propagation results are available and ready for analysis in the next steps.
Step 4: Analyze and interpret results#
As described earlier, the objective of uncertainty quantification is to understand how the cost of recovery changes under variations in market conditions and process-related parameters. In particular, we aim to identify which uncertain parameters have the greatest impact on the key performance indicator of interest—in this case, the cost of recovery.
A variety of analytical approaches can be applied to interpret the results. In this case study, the following analyses are demonstrated:
Sensitivity ranking
Statistical summary
Histogram visualization
Confidence interval estimation
Before performing any analysis, the simulation results must be cleaned. As observed in the output from the previous cell, some samples may terminate with warnings, infeasibility, or due to reaching the maximum number of solver iterations. Consequently, not all sampled cases yield valid optimized results.
Therefore, the first step in the analysis is to filter the dataset and retain only the cases with successful solver termination.
det_results = local_solver.solve(build_diafiltration_model)
pyo.assert_optimal_termination(det_results)
# Keep only successful solves
samples = choose_sampling(
build_diafiltration_model,
uncertain_parameters,
uncertainty_specs,
n_samples,
solver=local_solver,
random_seed=1,
)
valid = ~np.isnan(samples[1]) # Optimization objective: Cost of recovery
param_samples = samples[2][valid, :] # Valid parameter samples
recovery_cost_samples = samples[1][valid] # Valid cost of recovery
WARNING: non-optimal solve at sample 60: status=warning, term=infeasible
WARNING: non-optimal solve at sample 114: status=warning, term=infeasible
WARNING: non-optimal solve at sample 137: status=warning, term=infeasible
WARNING: non-optimal solve at sample 147: status=warning, term=infeasible
WARNING: non-optimal solve at sample 179: status=warning, term=infeasible
WARNING: non-optimal solve at sample 191: status=warning, term=infeasible
Step 4.1: Sensitivity analysis#
Two sensitivity analysis methods are applied to evaluate how uncertain parameters influence the optimization objective—minimizing the cost of recovery:
Standardized Linear Regression Coefficients (SLRC)
Pearson Correlation Coefficients
These methods quantify the relative impact of each uncertain parameter on the objective function.
Using two different sensitivity approaches allows for cross-validation of the results and helps ensure that the conclusions are not strongly biased by the choice of method. Consistency between the two analyses increases confidence in identifying the most influential parameters.
# Get parameter names for analysis
param_names = [p.getname() for p in uncertain_parameters]
# Sensitivity analysis
analyze_sensitivity = uq.analyze_sensitivity(
param_samples,
recovery_cost_samples,
param_names,
technology_name=None, # Default technology Case A is used.
)
#############################
Sensitivity analysis: technology
#############################
=== Sensitivity ranking (standardized linear coefficients) ===
Co_price |beta| = 7.02
income_tax_percentage |beta| = 5.85
Li_price |beta| = 0.961
royalty_charge_percentage_of_revenue |beta| = 0.639
operating_days_per_year |beta| = 0.418
membrane_cost |beta| = 0.239
factor_membrane_replacement |beta| = 0.205
Lang_factor |beta| = 0.192
electricity_cost |beta| = 0.0787
pump_efficiency |beta| = 0.0381
=== Sensitivity ranking (|Pearson correlation|) ===
Co_price |rho| = 0.75
income_tax_percentage |rho| = 0.629
Li_price |rho| = 0.207
Lang_factor |rho| = 0.174
electricity_cost |rho| = 0.155
royalty_charge_percentage_of_revenue |rho| = 0.13
operating_days_per_year |rho| = 0.0755
pump_efficiency |rho| = 0.0613
membrane_cost |rho| = 0.0221
factor_membrane_replacement |rho| = 0.0191
As shown in the results table above, both sensitivity analysis methods indicate that the three most influential uncertain parameters are cobalt price, income tax rate, and lithium price.
In contrast, parameters primarily associated with fixed costs—such as membrane cost, pump efficiency, and membrane replacement factor—exhibit relatively low sensitivity with respect to the cost of recovery.
This suggests that market-driven price variables have a stronger impact on economic performance than certain process-related cost parameters under the assumptions of this case study.
Step 4.2: Uncertainty propagation and quantiles#
The uncertainties in the input parameters are propagated through the model to evaluate their impact on the output—specifically, the cost of recovery.
This analysis helps quantify the overall economic uncertainty associated with the process and supports risk-informed decision making.
# Single technology histogram and confidence interval
plt.hist(recovery_cost_samples, bins=30, density=True, alpha=0.5)
plt.title("Cost of recovery histogram")
plt.xlabel("Cost of recovery (USD/kg)")
plt.ylabel("Density")
# Mark key quantiles
rec = np.asarray(samples[1], dtype=float) # Cost of recovery
valid_cost_of_recovery = rec[~np.isnan(rec)]
if valid_cost_of_recovery.size > 0:
q5, q50, q95 = np.percentile(valid_cost_of_recovery, [5, 50, 95])
plt.axvline(q5, linestyle="--", linewidth=2, color="tab:blue")
plt.axvline(q50, linestyle="-.", linewidth=2, color="tab:orange")
plt.axvline(q95, linestyle="--", linewidth=2, color="tab:red")
plt.legend(
[f"5%: {q5:.4g}", f"50%: {q50:.4g}", f"95%: {q95:.4g}"],
fontsize=8,
)
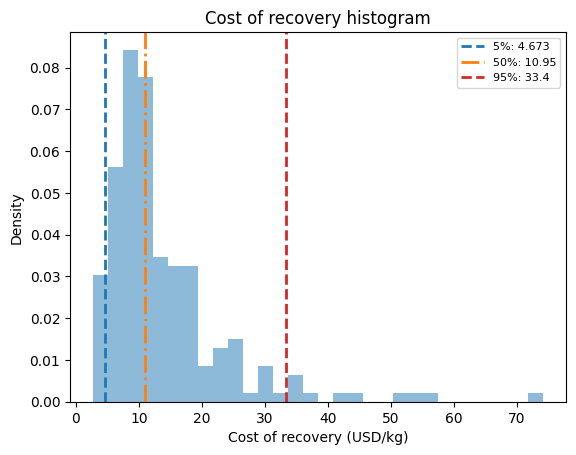
As shown in the figure above, the mode of the cost of recovery is approximately 10.95 \(\$/\text{kg}\). However, the cost increases to approximately 33.4 \(\$/\text{kg}\) at the 95th percentile, meaning that 95% of the uncertainty samples result in a cost of recovery at or below this value while still satisfying the recovery criteria.
It is also informative to examine how the decision variables adjust under uncertainty, as this provides additional insight into how the optimization responds to varying market and process conditions.
# Plot membrane length histogram
fig, axes = plt.subplots(1, 3, figsize=(20, 6))
L1 = np.asarray(samples[3], dtype=float)[valid] # stage1_len
L2 = np.asarray(samples[4], dtype=float)[valid] # stage2_len
L3 = np.asarray(samples[5], dtype=float)[valid] # stage3_len
axes[0].hist(L1[~np.isnan(L1)], bins=30, density=True, alpha=0.7)
axes[0].set_title(f"Stage 1 length")
axes[0].set_xlabel("Length (m)")
axes[0].set_ylabel("Density")
axes[1].hist(L2[~np.isnan(L2)], bins=30, density=True, alpha=0.7)
axes[1].set_title(f"Stage 2 length")
axes[1].set_xlabel("Length (m)")
axes[1].set_ylabel("Density")
axes[2].hist(L3[~np.isnan(L3)], bins=30, density=True, alpha=0.7)
axes[2].set_title(f"Stage 3 length")
axes[2].set_xlabel("Length (m)")
axes[2].set_ylabel("Density")
plt.tight_layout()
plt.show()
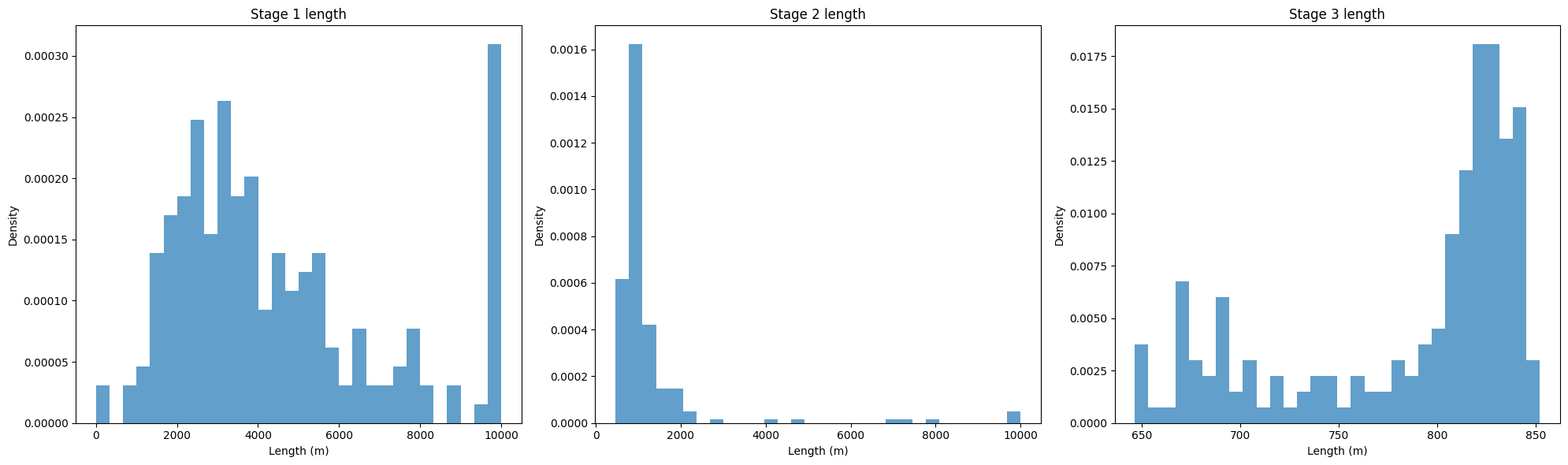
The figure above indicates that, under uncertainty, the minimized cost of recovery is most strongly influenced by the membrane length in Stage 1, followed by Stage 2, while Stage 3 has the least impact.
The optimized membrane length for Stage 3 typically falls within the range of approximately 650–850 m. Considering the uncertainty in both market and process parameters, selecting membrane lengths of approximately 3800 m, 1000 m, and 830 m for Stages 1, 2, and 3, respectively, is most likely to achieve a low cost of recovery.
Descriptive statistics can be generated to further characterize system behavior under uncertainty.
print(f"\n=== Summary statistics ===")
print(f"Valid samples: {valid_cost_of_recovery.size}/{n_samples}")
if valid_cost_of_recovery.size > 0:
mean_cost = np.mean(valid_cost_of_recovery)
std_cost = np.std(valid_cost_of_recovery, ddof=1)
q5, q50, q95 = np.percentile(valid_cost_of_recovery, [5, 50, 95])
print(f"Mean cost_of_recovery: {mean_cost:.6f}")
print(f"Std cost_of_recovery: {std_cost:.6f}")
print(f"5% / 50% / 95% quantiles: {q5:.6f}, {q50:.6f}, {q95:.6f}")
=== Summary statistics ===
Valid samples: 194/200
Mean cost_of_recovery: 14.015414
Std cost_of_recovery: 10.152837
5% / 50% / 95% quantiles: 4.673315, 10.947269, 33.399444
The results indicate that the mean cost of recovery under uncertainty is 14.02 \(\$/kg\), with standard deviation of 10.15. Furthermore, there is a 95% probability that the cost of recovery will be below 33.40 \(\$/kg\).
Step 4.3: Compare technologies#
The framework also allows for the comparison of different technologies under the same uncertainty assumptions. In the example below, alternative technologies are represented by different membrane sieving coefficients.
This approach can be extended to compare entirely different process configurations that produce lithium and cobalt. However, it is important to note that alternative processes may introduce additional unit-model-specific uncertainties and parameters that must be carefully defined and incorporated into the uncertainty analysis.
Please note that the following section compares two different technologies, each evaluated with 200 samples. This section will take approximately four minutes to complete.
technologies = {
"Li_sc=1.3, Co_sc=0.5": (1.3, 0.5),
"Li_sc=1.5, Co_sc=0.8": (1.5, 0.8),
}
results_by_technology = {}
for technology_name, sieving_coeffs in technologies.items():
print(f"\n=== Running technology {technology_name} ===")
m = uq.build_diafiltration_model(
sieving_coeffs=sieving_coeffs, technology_name=technology_name
)
uq.decision_variables_bounds(m)
det_results = local_solver.solve(m)
pyo.assert_optimal_termination(det_results)
det_obj = pyo.value(m.fs.costing.cost_of_recovery)
print(f"Deterministic optimal cost_of_recovery: {det_obj:.6f}")
uncertain_params = uq.identify_uncertain_params(m)
param_names = [p.getname() for p in uncertain_params]
# rebuild specs for this model
cp = m.fs.costing
lognormal_params_this = {
cp.electricity_cost.getname(): {"mu": mu_elec, "sigma": sigma_elec},
cp.Li_price.getname(): {"mu": mu_li, "sigma": sigma_li},
cp.Co_price.getname(): {"mu": mu_co, "sigma": sigma_co},
}
uncertainty_specs_this = uq.build_uncertainty_specs(
m, lognormal_params=lognormal_params_this, income_tax_samples=income_tax_samples
)
samples = choose_sampling(
m,
uncertain_params,
uncertainty_specs_this,
n_samples,
solver=local_solver,
random_seed=1,
)
(
samples_first_param,
recovery_cost_samples,
param_samples,
stage1_len,
stage2_len,
stage3_len,
) = samples
valid = ~np.isnan(recovery_cost_samples)
param_names = [p.getname() for p in uncertain_params]
results_by_technology[technology_name] = dict(
samples_first_param=samples_first_param,
recovery_cost_samples=recovery_cost_samples,
param_samples=param_samples,
stage1_len=stage1_len,
stage2_len=stage2_len,
stage3_len=stage3_len,
valid=valid,
det_obj=det_obj,
param_names=param_names,
m=m,
)
valid_cost = recovery_cost_samples[valid]
print(f"\n=== Summary statistics: {technology_name} ===")
print(f"Valid samples: {valid_cost.size}/{n_samples}")
if valid_cost.size:
print("Mean:", np.mean(valid_cost), "Std:", np.std(valid_cost, ddof=1))
=== Running technology Li_sc=1.3, Co_sc=0.5 ===
2026-04-23 15:28:12 [INFO] idaes.init.fs.stage1: Stream Initialization Completed.
2026-04-23 15:28:12 [INFO] idaes.init.fs.stage1: Initialization Completed, optimal - <undefined>
2026-04-23 15:28:12 [INFO] idaes.init.fs.mix1: Initialization Complete: optimal - <undefined>
2026-04-23 15:28:12 [INFO] idaes.init.fs.stage2: Stream Initialization Completed.
2026-04-23 15:28:12 [INFO] idaes.init.fs.stage2: Initialization Completed, optimal - <undefined>
2026-04-23 15:28:13 [INFO] idaes.init.fs.mix2: Initialization Complete: optimal - <undefined>
2026-04-23 15:28:13 [INFO] idaes.init.fs.stage3: Stream Initialization Completed.
2026-04-23 15:28:13 [INFO] idaes.init.fs.stage3: Initialization Completed, optimal - <undefined>
2026-04-23 15:28:13 [INFO] idaes.init.fs.stage3: Stream Initialization Completed.
2026-04-23 15:28:13 [INFO] idaes.init.fs.stage3: Initialization Completed, optimal - <undefined>
Deterministic optimal cost_of_recovery: 0.032835
WARNING: non-optimal solve at sample 60: status=warning, term=infeasible
WARNING: non-optimal solve at sample 114: status=warning, term=infeasible
WARNING: non-optimal solve at sample 137: status=warning, term=infeasible
WARNING: non-optimal solve at sample 147: status=warning, term=infeasible
WARNING: non-optimal solve at sample 179: status=warning, term=infeasible
WARNING: non-optimal solve at sample 191: status=warning, term=infeasible
=== Summary statistics: Li_sc=1.3, Co_sc=0.5 ===
Valid samples: 194/200
Mean: 14.01541365370703 Std: 10.152837265032286
=== Running technology Li_sc=1.5, Co_sc=0.8 ===
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage1: Stream Initialization Completed.
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage1: Initialization Completed, optimal - <undefined>
2026-04-23 15:29:07 [INFO] idaes.init.fs.mix1: Initialization Complete: optimal - <undefined>
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage2: Stream Initialization Completed.
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage2: Initialization Completed, optimal - <undefined>
2026-04-23 15:29:07 [INFO] idaes.init.fs.mix2: Initialization Complete: optimal - <undefined>
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage3: Stream Initialization Completed.
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage3: Initialization Completed, optimal - <undefined>
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage3: Stream Initialization Completed.
2026-04-23 15:29:07 [INFO] idaes.init.fs.stage3: Initialization Completed, optimal - <undefined>
Deterministic optimal cost_of_recovery: 0.064390
WARNING: non-optimal solve at sample 128: status=warning, term=infeasible
WARNING: non-optimal solve at sample 135: status=warning, term=infeasible
=== Summary statistics: Li_sc=1.5, Co_sc=0.8 ===
Valid samples: 198/200
Mean: 14.330419057601931 Std: 10.397691032885659
From the results above, it can be observed that increasing the sieving coefficient leads to a slight increase in the mean cost of recovery. Examining the optimized membrane lengths shown below suggests that this increase is likely driven by a longer membrane length in Stage 1.
A higher membrane length is required to achieve the desired separation performance for lithium and cobalt, which in turn contributes to the increase in recovery cost.
# Sensitivity analysis
for tech, d in results_by_technology.items():
print(f"\n=== Sensitivity: {tech} ===")
uq.analyze_sensitivity(
d["param_samples"],
d["recovery_cost_samples"],
d["param_names"],
technology_name=tech,
)
=== Sensitivity: Li_sc=1.3, Co_sc=0.5 ===
#############################
Sensitivity analysis: Li_sc=1.3, Co_sc=0.5
#############################
=== Sensitivity ranking (standardized linear coefficients) ===
Co_price |beta| = 7.02
income_tax_percentage |beta| = 5.85
Li_price |beta| = 0.961
royalty_charge_percentage_of_revenue |beta| = 0.639
operating_days_per_year |beta| = 0.418
membrane_cost |beta| = 0.239
factor_membrane_replacement |beta| = 0.205
Lang_factor |beta| = 0.192
electricity_cost |beta| = 0.0787
pump_efficiency |beta| = 0.0381
=== Sensitivity ranking (|Pearson correlation|) ===
Co_price |rho| = 0.75
income_tax_percentage |rho| = 0.629
Li_price |rho| = 0.207
Lang_factor |rho| = 0.174
electricity_cost |rho| = 0.155
royalty_charge_percentage_of_revenue |rho| = 0.13
operating_days_per_year |rho| = 0.0755
pump_efficiency |rho| = 0.0613
membrane_cost |rho| = 0.0221
factor_membrane_replacement |rho| = 0.0191
=== Sensitivity: Li_sc=1.5, Co_sc=0.8 ===
#############################
Sensitivity analysis: Li_sc=1.5, Co_sc=0.8
#############################
=== Sensitivity ranking (standardized linear coefficients) ===
Co_price |beta| = 7.09
income_tax_percentage |beta| = 6.02
Li_price |beta| = 0.999
royalty_charge_percentage_of_revenue |beta| = 0.753
operating_days_per_year |beta| = 0.46
membrane_cost |beta| = 0.282
Lang_factor |beta| = 0.169
electricity_cost |beta| = 0.157
factor_membrane_replacement |beta| = 0.141
pump_efficiency |beta| = 0.0259
=== Sensitivity ranking (|Pearson correlation|) ===
Co_price |rho| = 0.745
income_tax_percentage |rho| = 0.637
Li_price |rho| = 0.207
Lang_factor |rho| = 0.169
royalty_charge_percentage_of_revenue |rho| = 0.158
electricity_cost |rho| = 0.137
operating_days_per_year |rho| = 0.102
pump_efficiency |rho| = 0.0555
factor_membrane_replacement |rho| = 0.0327
membrane_cost |rho| = 0.00159
Both technologies exhibit the same sensitivity ranking, suggesting that their underlying cost structures and parameter influences are closely aligned. Which means that under these two technologies, the priority way to reduce cost is the same.
# ---------- PLOT ----------
techs = list(results_by_technology.keys())
ntech = len(techs)
# (A) 2 rows x 3 cols: stage length histograms
fig, axes = plt.subplots(ntech, 3, figsize=(18, 4 * ntech), squeeze=False)
for r, tech in enumerate(techs):
d = results_by_technology[tech]
valid = d["valid"]
L1 = np.asarray(d["stage1_len"], dtype=float)[valid]
L2 = np.asarray(d["stage2_len"], dtype=float)[valid]
L3 = np.asarray(d["stage3_len"], dtype=float)[valid]
axes[r, 0].hist(L1, bins=30, density=True, alpha=0.7)
axes[r, 0].set_title(f"Stage 1 Length\n{tech}")
axes[r, 0].set_xlabel("Length (m)")
axes[r, 0].set_ylabel("Density")
axes[r, 1].hist(L2, bins=30, density=True, alpha=0.7)
axes[r, 1].set_title(f"Stage 2 Length\n{tech}")
axes[r, 1].set_xlabel("Length (m)")
axes[r, 1].set_ylabel("Density")
axes[r, 2].hist(L3, bins=30, density=True, alpha=0.7)
axes[r, 2].set_title(f"Stage 3 Length\n{tech}")
axes[r, 2].set_xlabel("Length (m)")
axes[r, 2].set_ylabel("Density")
plt.tight_layout()
plt.show()
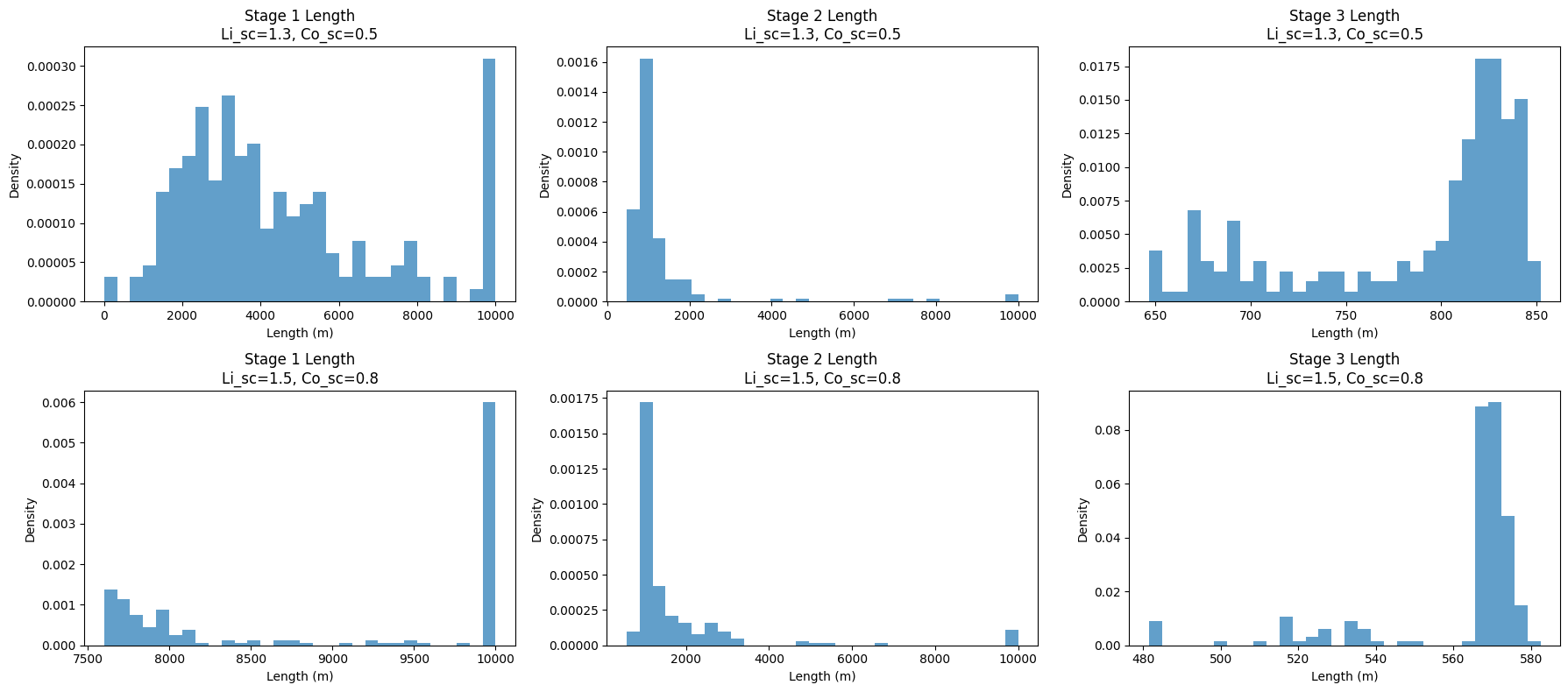
The optimized membrane lengths shift slightly between the two technologies. As the sieving coefficients increase, the membrane length ranges for Stages 1 and 3 become narrower, and the corresponding density values increase. This suggests that, for a given fixed membrane length, the technology with sieving coefficients of (1.5, 0.8) has a higher probability of achieving lithium and cobalt recovery within a specified cost range.
# (B) Cost_of_recovery comparison
fig, axes = plt.subplots(1, ntech, figsize=(6 * ntech, 4), squeeze=False)
axes = axes[0]
for k, tech in enumerate(techs, start=0):
d = results_by_technology[tech]
rec = np.asarray(d["recovery_cost_samples"], dtype=float)
valid = rec[~np.isnan(rec)]
axes[k].hist(valid, bins=30, density=True, alpha=0.7)
axes[k].set_title(f"Cost of Recovery\n{tech}")
axes[k].set_xlabel("USD/kg")
axes[k].set_ylabel("Density")
# Mark key quantiles (valid only)
if valid.size > 0:
q5, q50, q95 = np.percentile(valid, [5, 50, 95])
axes[k].axvline(q5, linestyle="--", linewidth=2, color="tab:blue")
axes[k].axvline(q50, linestyle="-.", linewidth=2, color="tab:orange")
axes[k].axvline(q95, linestyle="--", linewidth=2, color="tab:red")
axes[k].legend(
[f"5%: {q5:.4g}", f"50%: {q50:.4g}", f"95%: {q95:.4g}"],
fontsize=8,
)
plt.tight_layout()
plt.show()
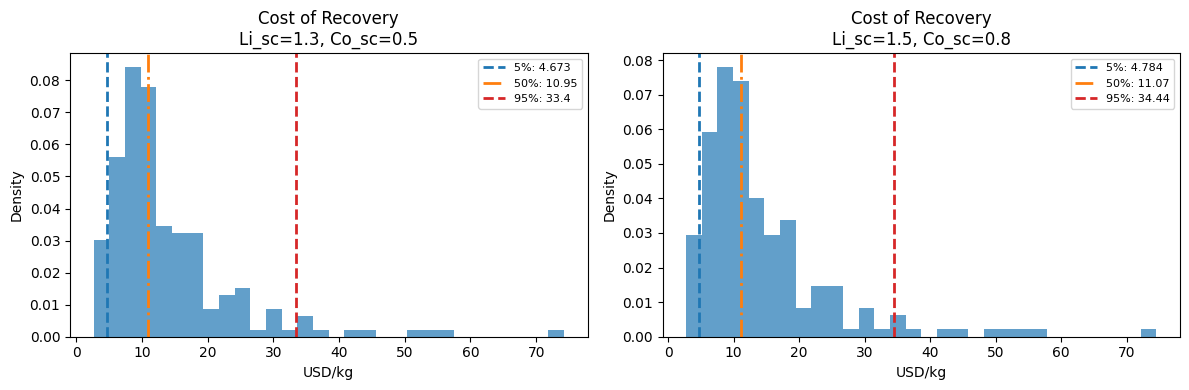
Although the optimized membrane lengths differ between the two technologies, the impact on the cost of recovery is relatively small, with only a slight increase observed for the (1.5, 0.8) case.
Despite substantial differences in the optimized membrane lengths, the distributions of the cost of recovery remain highly similar across the two scenarios. This behavior is consistent with the sensitivity analysis, which indicates that membrane-related parameters—such as membrane cost and replacement factors—have relatively low influence on the overall cost of recovery. Consequently, even large variations in membrane length result in only modest changes in total recovery cost.